
TFTT #18 – Être de l’IA, ou ne pas être de l’IA : telle est la question [Interview Label4.AI] 🗣

![TFTT #18 – Être de l’IA, ou ne pas être de l’IA : telle est la question [Interview Label4.AI] 🗣](/content/images/size/w2000/2025/08/last-action-hero-photo-last-action-hero-1002644.jpg)
Ce mois-ci dans Tales from the Tech, nous allons à nouveau discuter d'intelligence artificielle générative, mais d'une manière différente, et avec un invité de (water)marque.
Vous ne comprenez pas encore la boutade ? C'est normal 😇
Cet invité va nous aider à répondre à une question :
Avec l'avènement de l'IA générative, on assiste à ce que certain.e.s appellent le "pourrissement d'internet", une ère en ligne où il devient difficile de distinguer ce qui est vrai de ce qui est faux. Alors : des méthodes existent-elles pour parvenir à maintenir cette distinction ?
Cet invité, c'est Nicolas Bodin Guittard, l'un des co-fondateurs de Label4AI, et on va se parler de ce que fait son entreprise, de pourquoi "tatouer" les contenus générés par l'IA est important... et de souveraineté numérique, aussi.
On vous a fait suivre cette newsletter ? Pensez à vous inscrire via le bouton !
Vous pouvez également soutenir mon travail à hauteur de 1, 3 ou 5€ / mois, ou bien faire un don ponctuel 🙏
De retour à l'ère de la rumeur ?
Avec la victoire du Brexit en juin 2016 puis l'arrivée au pouvoir de Trump pour la première fois en janvier 2017, nous découvrions l'ère de la post-vérité. Nous entrions dans une période formidable où dire la vérité n'était plus important, c'était dire ce que les gens veulent entendre qui comptait, et surtout le dire plus fort que le voisin.
Avec l'avènement de l'intelligence artificielle générative quelques années plus tard, et la frénésie qui entoure cette technologie depuis, il ne faut pas s'étonner de voir le second mandat de Trump marquer un rapprochement inédit entre le camp du président d'extrême droite états-unien et les grandes entreprises de la tech, principalement états-uniennes elles-aussi.
Ces dernières sont prêtes à tout pour voir le traffic augmenter sur leurs plateformes, peu importe la nature des messages et des contenus qui y sont partagés, peu importe que cela mette en danger les individus et les organisations.
Nous sommes donc dans l’ère du doute permanent, en ligne : tout ce que vous lisez, tout ce que vous voyez sur internet peut être faux, puisque produit par des machines sans qu'on connaisse bien les intentions des auteurs derrière, ou la fiabilité desdites machines, entre hallucinations et omissions.
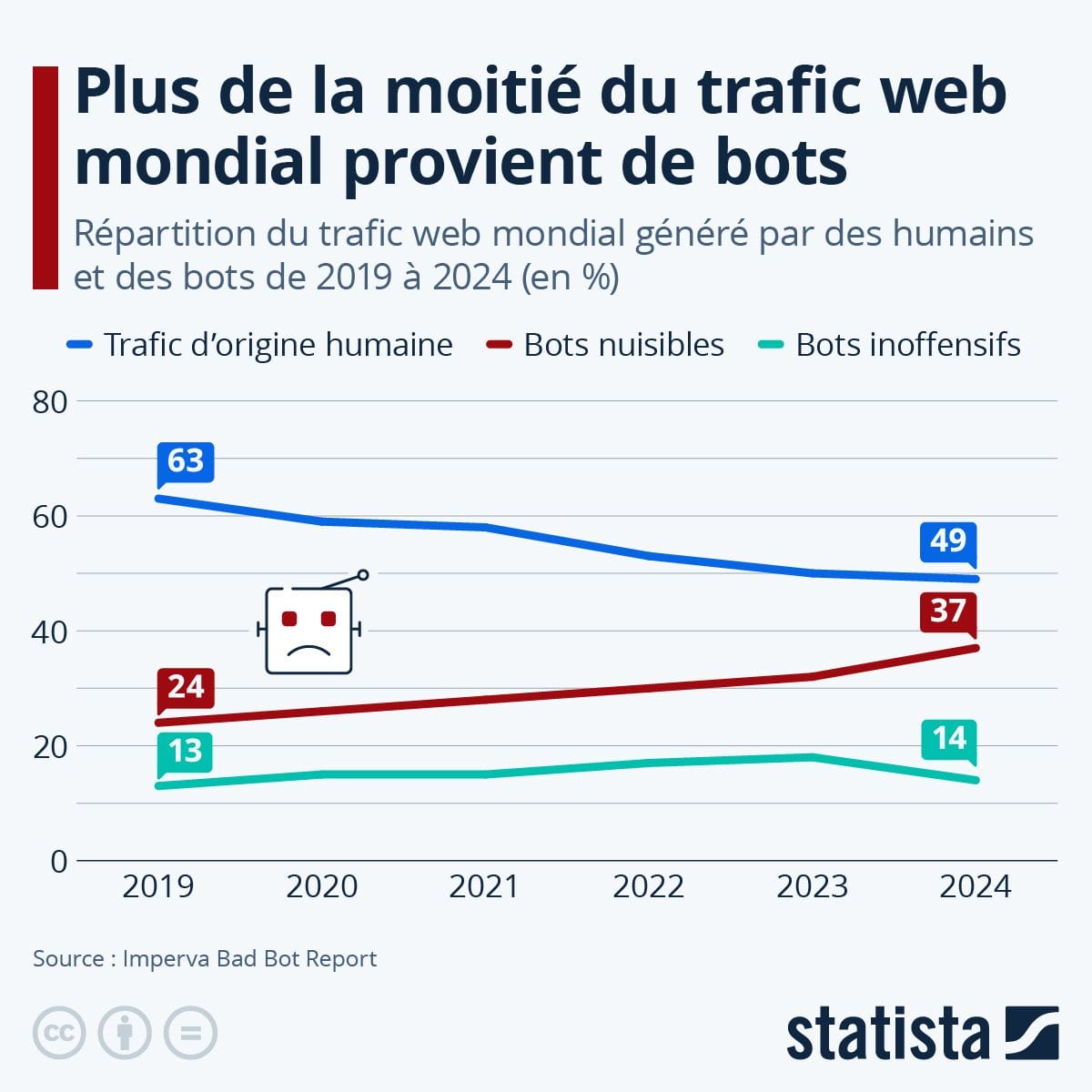
Qui croire alors, de qui se méfier ?
Alors que le "monde moderne" et "l'ère de l'information" devait nous apporter une meilleure compréhension commune du monde et donc rapprocher les peuples et les individus, la fatigue informationnelle poussée par des outils de production à la chaîne de contenus synthétiques pourrait parvenir à déliter ce qu'il nous restait au moins en commun : le réel.
Serions-nous donc de retour à l'ère de la rumeur, quand les dragons sur les cartes marines passaient pour réels ?
Pas encore.
Mais dans ce contexte, il est plus primordial que jamais de savoir ce qui a été généré par une IA, ou ce qui a été réalisé par la "main" de l'humain.

"Être de l’IA ou ne pas être de l’IA, telle est la question."
Voilà comment je résumerais en une phrase référencée la mission primordiale que s'est fixé Nicolas Bodin Guittard avec son projet Label4AI, spécialisé dans la traçabilité des contenus générés par IA. Il en est le CEO, comme on dit dans le monde des startups. Le Directeur Général, en somme.
Dans un monde où, on l'a vu, il devient de plus en plus difficile de distinguer le vrai du faux, développer des outils qui permettent de savoir ce qui a été généré par l'IA ou pas devient une question de vie ou de mort... pour nos démocraties de manière globale, comme pour toute entreprise ou organisation. Sans parler de notre santé mentale individuelle et collective.
⚠ Avertissement important : à la différence du premier entretien que j'avais réalisé avec Will Alpine, Nicolas et moi nous connaissons bien. Nous nous sommes rencontrés chez Shadow, l'entreprise de cloud computing rachetée en 2021 par Octave Klaba avec de grandes ambitions autour des enjeux de souveraineté numérique. Il en était le directeur juridique, j'en étais le directeur de la communication.
Même si nos visions de l'IA, notamment générative, diffèrent sur certains points, nous partageons le même constat d'un besoin d'encadrer et de légiférer sur le sujet. C'est cette constatation commune qui a mené à l'entretien que vous allez lire aujourd'hui.
Un entretien au cours duquel j'ai appris beaucoup de choses, et mieux compris le fonctionnement même des IA génératives. J'espère qu'il en sera de même pour vous.
Bonne lecture 🤗

Salut Nicolas, merci beaucoup de répondre à mes questions pour Tales from the Tech. Tu es le co-fondateur de Label4AI, une entreprise dont le boulot est marquer et détecter les contenus générés par l’IA. Comment toi, tu définirais la mission de ce projet ?
Nicolas Bodin Guittard : Je commencerais par les bases : l’IA générative, c’est quoi ? Ce sont des contenus qui ressemblent à la réalité, produits de façon « cheap », en masse, par potentiellement n'importe qui. Cette production, elle perturbe tous les processus qui sont en place dans les entreprises et les organisations. Nous, on veut apporter une solution technologique qui permet de maintenir l'équilibre pour que ces structures puissent garder le contrôle, dans un contexte où l’IA générative vient tout bousculer.
Concrètement cela veut dire quoi ? Cela veut dire taguer le contenu "synthétique" dès sa naissance – ce qu’on appelle le watermark – et donner les outils pour détecter ce "tatouage numérique" dès qu'on y est confronté. On retrouve cette dualité en permanence. Taguer et détecter les contenus pour connaître leur vraie nature, pour éviter toute confusion entre ce qui est généré par l’IA, et ce qui ne l’est pas.
C’est une précision importante : nous ne sommes pas du tout « contre l'IA ». Au contraire, je trouve que c'est une technologie très intéressante ; modulo les aspects écologiques qui te sont chers et auxquels je suis également sensible. En revanche, c'est une techno qui, compte tenu de ses paramètres, est aussi un eldorado pour les fraudeurs et les gens malhonnêtes.

Je te demanderai après de rentrer dans le détail technique de ce watermark, parce que c’est la clé de tout ici... Mais avant ça, tu peux m’expliquer comment tu en es arrivé à ce projet ?
NBG : Je viens du monde du droit. J’ai eu un parcours juridique classique, et j'ai fait mes armes dans des cabinet d'avocats, avec de rejoindre de grosses boites, notamment TF1. J'ai ensuite embrayé assez rapidement sur les startups, à partir de 2015, avec un angle tech net, et toujours avec la notion de souveraineté [numérique] en toile de fond. Cette dernière dimension, je l’ai retrouvé au départ un peu par hasard, puis par conviction. C’est ce qui m’a amené chez Shadow et Qwant [N.d.A. : entreprises où nous nous sommes donc rencontrés, les deux ayant été regroupées dans une même structure suite aux rachats successifs d’Octave Klaba].
J'ai ensuite rencontré un groupe de chercheurs rennais qui avait un projet ambitieux autour de la détection des contenus IA, avec des profils techniques très solides. Le sujet m'intéressait déjà beaucoup, et ils avaient besoin de quelqu’un pour apporter la dimension juridique au projet et structurer l’activité. On est maintenant six co-fondateurs, avec des profils très "deep tech", la plupart sont des doctorants/PhD en informatique appliquée, avec entre 15 et 20 ans de métier.
C’est là que la complémentarité intervient : comme avec Label4AI on est entre la tech et le réglementaire, ça se complète très bien, puisqu’Anthony [Level, le CSO de l'entreprise] et moi sommes les deux personnes "non-tech" de l’équipe. Lui sur la partie affaires publiques, moi sur la partie juridique. Cela nous permet d’avoir une très bonne compréhension des réglementations autour de l'IA, notamment de l’AI Act. Compréhension du contexte, des impacts que cette réglementation peut avoir, de la traçabilité que ça demande, etc.
Nous sommes aussi très liés à la recherche [N.d.A. : notamment avec l'INRIA et le CNRS en France ou l’Université de Naples en Italie], ce qui se traduit par beaucoup d’échanges avec des facs et laboratoires de recherche. On souhaite participer à l'application industrielle des travaux académiques, ce qui représente souvent une étape difficile : passer du laboratoire à la "vraie vie".
Tu l’as esquissé ici, ton projet est par définition complexe et technique. Comment tu arriverais à expliquer comment marche ce "watermarking", cet tatouage numérique que tu évoquais ?
NBG : Je vais commencer par une précision clé : le "watermarking", c'est une fonctionnalité, ce n'est pas une technologie. Et c’est une fonctionnalité qui date : elle existe sous différentes natures depuis plus de 30 ans. Ce qui diffère ici, c’est notre façon de l’appliquer au contenu généré par IA. Le watermarking, c'est un principe selon lequel un élément invisible est inséré dans un contenu, ce qui permet sa traçabilité ultérieure. On vient incruster dans le contenu, très en profondeur et de manière invisible, sa carte d'identité, infalsifiable. Comme le filigrane des billets de banque, en quelque sorte.
Disons, pour simplifier, qu’il existe aujourd’hui 3 types de watermarking, en fonction des formats les plus communs de contenus générés par IA :
Primo, il y a l'image : on modifie l'image au niveau des pixels. On pose un "masque" sur l’image, spécifique à ses éléments saillants. Quand c’est bien fait, c’est complètement invisible ; quand c’est mal fait, ça peut modifier des éléments comme la colorimétrie de l’image… Ensuite, avec le détecteur approprié, on peut déterminer que c'est bien l'image à laquelle on fait référence, ou bien vérifier sa provenance, selon les critères du "tag".
Après son invisibilité, un autre point clé d’un watermark c’est sa robustesse : quelques soient les modifications et les "attaques" faites à l’image, on doit pouvoir retrouver le tag. Dans notre cas, même si quelqu’un vient prendre en photo l’image watermarké sur ton écran d’ordinateur avec un autre appareil, par exemple, et bien le tag restera fonctionnel. Idem en cas de compression, ou de réencodage de l'image. De ce point de vue, c'est la méthode la plus robuste.
Deuxio, sur l’audio. Il y a plusieurs manières de watermarker un fichier audio, mais la meilleure façon de le faire selon nous (et en simplifiant le concept) c’est de jouer sur les fréquences inaudibles, pour ajouter au contenu généré une marque que seul un algorithme spécialisé pourra "entendre".
Enfin pour le texte, c’est le plus complexe : comme un LLM [N.d.A. : Large Language Model, grand modèle de language en français, dont l'exemple le plus connu est bien sûr ChatGPT] est un modèle statistique, on vient tester les pourcentages de probabilité. Pour simplifier : un LLM génère du texte mot par mot, chaque mot étant ce qu'on appelle un "token". Chaque mot se voit attribué un score de probabilité, basé sur la probabilité qu'il soit généré ensuite. Par exemple, dans la phrase "mes animaux de compagnie préférés sont les chats et...", le mot "chien" aura un score de probabilité plus élevé que le mot "voiture". Là, on vient ajuster ces scores de probabilité pour générer un watermark invisible en choisissant le mot que le LLM aurait choisi en deuxième, et qui n'affecte pas le sens et la qualité du résultat.
Ce qui est sûr, c’est que seul le watermark permet une détection fiable de ce type de contenus. Soyons clairs : les systèmes de détection de textes générés disponibles facilement en ligne pour savoir si un texte est généré ou non ne sont pas fiables ! Ça peut fonctionner en trouvant des "patterns", mais il y a un énorme problème de faux positifs.
Il existe d’autres méthodes que le watermarking pour "marquer" les contenus générés par IA comme tel. Peux-tu m’en dire plus, et m’expliquer pourquoi vous, vous avez opté pour le watermarking ?
NBG : Il y a en effet d’autres méthodes de "tag" pour identifier les contenus qui sont générés avec de l’IA. Celle dont on parle le plus, c’est la "metadata", ou métadonnée. Tu ajoutes simplement dans les données du fichier, quelle que soit sa nature, que ledit fichier est créé via un outil d’IA générative, et lequel. Basta.
Il y a aussi la méthode du "fingerprinting", qui demande à ce que tous les contenus générés par IA aient une "empreinte digitale" distincte, disponible dans une énorme base de donnée. Une espèce de Shazam, pour résumer grossièrement. Il y a enfin des méthodes qui se basent sur une utilisation de la blockchain.
Chacune de ces méthodes doit être évaluée selon quatre critères : efficacité, interopérabilité, robustesse et accessibilité.
Le truc, c’est que selon nous, aucune méthode n'est aussi fiable que le watermarking. Pour revenir aux métadonnées, l'un des modèles le plus connu est le C2PA, porté notamment par Adobe. Il est intéressant, mais n'est clairement pas le plus robuste, et doit être envisagé avec d'autres solutions en parallèle. Quelqu'un a par exemple réussi à faire dire aux metadatas que la fameuse photo du Pape en doudoune était une photo officielle du Vatican ! Ça, ce n’est pas possible avec le watermark.

Du côté étatique, c'est également la méthode du watermarking qui est généralement suggérée, parce que c'est celle qui propose le meilleur compromis entre robustesse, sécurité et facilité de déploiement.
Parce que si le watermarking, comme toute méthode de tag, génère des faux positifs… il le fait beaucoup moins que les autres : environ 1 pour 1 milliard, pour notre propre méthode de watermarking. C'est rien. D'autres techniques, pourtant avancées, produisent un faux positif pour 1 000, au mieux. C'est donc beaucoup moins fiable, et utiliser à grande échelle, cela va générer beaucoup d'erreurs.
Notre vocation, ce n’est pas de rendre les "deep fake" impossibles, parce qu’aucune méthode n’est fiable à 100%. Mais à l’heure actuelle, le watermarking est la méthode la plus fiable, la plus dure à "craquer", compte tenu des paramètres qu'on doit mettre en œuvre.
Maintenant, ce watermarking, il faut qu’il soit bien fait. On a un concurrent, que je ne citerai pas, qui a proposé sa propre méthode de watermark. Ils ont sorti leur modèle, et honnêtement : on l'a craqué en dix minutes. C'est hyper dangereux. Il vaut mieux pas de watermark, qu’un watermark de mauvaise qualité qui offre l'illusion de la sécurité. Sinon, après, on peut imaginer un hacker qui sait imiter la technique de watermarking d’une entreprise et fait passer un faux document pour un vrai… Là, ça peut aller très vite. Ça participerait à saper la confiance du public dans la notion de watermarking.
Surtout, pour conclure, je dirais qu'aucune méthode de tag seule n'est magique. Mais pour nous, le socle le plus sûr reste donc le watermark.
Je fais une parenthèse, mais, à propos d'impact environnemental : parmi toutes les méthodes, le tatouage est la plus intéressante, parce que ce n’est que quelques pixels à superposer sur le fichier. Comme il va falloir monter à l'échelle pour imposer un modèle, on va se parler d’énormes quantités de tatouages numériques à apposer. Donc, si à chaque fois que tu génères quelques chose, tu dois apposer un tag, il faut avoir la chose le plus légère possible. C’est le cas avec le watermark. À l'inverse, les métadonnées, par exemple, alourdissent considérablement chaque fichier généré.
L’orientation de Label4AI est uniquement professionnelle à ce stade. Il y a une vision à moyen, long terme pour aller aussi vers le grand public ?
NBG : Bien sûr, puisqu'à la fin, c'est le public qui compte. Mais c'est un peu le paradoxe de notre entreprise et de notre marché : on a besoin des entreprises pour protéger les consommateurs.
Je m’explique : que tout un chacun ait la capacité à marquer les contenus comme générés par IA ne va pas régler le problème. On s'en fout un peu que quelqu’un puisse utiliser un détecteur pour déterminer si les petits lapins sont vrais ou faux. Ce qu'il faut, à grande échelle et de façon systémique, c’est que les entreprises se saisissent du sujet. L’enjeu, c’est qu’il faut pouvoir lutter contre des campagnes massives de fraude qui déferlent sur les entreprises et leurs clients, qu’ils soient professionnels ou particuliers.
Il faut rappeler qu’à partir de 2026, le tag des contenus générés par IA sera obligatoire pour toutes les entreprises présentes en Europe, comme le stipule l'article 50 de l'AI Act, tandis que la Chine le recommande aussi, et l'Inde ne devrait plus tarder. C’était le cas aux États-Unis il n’y a pas si longtemps, mais Trump 2 est arrivé… ce qui n'empêche pas la Californie d'avancer sur le sujet. Bref : c’est donc par là qu’il faut prendre le truc.
Donc pour revenir à ta question initiale : on s’adresse à des entreprises, mais le but in fine, c’est d’afficher à tous les utilisateurs quels contenus ont été générés ou modifiés à l’aide de l’intelligence artificielle.

Tu as beaucoup parlé de la fraude, mais y’a-t-il d’autres domaines d’application qui vont être importants pour vous ?
NBG : Honnêtement, le cœur de notre activité cela va être de détecter la fraude, ou d'assainir l’écosystème pour prévenir cette fraude. Aujourd’hui, il est clair que toutes les entreprises qui proposent de l’IA générative devraient marquer leur contenu.
Or, certains comme Google et Meta le font pour des raisons avant tout pratiques, c'est-à-dire ne pas ré-entraîner leur propre système sur des choses déjà générés [N.d.A. : une des raisons du ralentissement des progrès des LLM]... même si les raisons éthiques arrivent, poussées par la réglementation. Il y a tout de même des variantes : une vidéo générée par Veo3 sera estampillée comme synthétique sur Youtube, mais pas sur Facebook et Instagram.
Par ailleurs, quand tu as des entreprises, comme ElevenLabs, qui permettent de faire de la reproduction vocale à partir de quelques secondes d'échantillon, il y a une obligation morale et éthique majeure à la mise en place d’un système qui permette de déterminer si on est face à du contenu synthétique ou non.
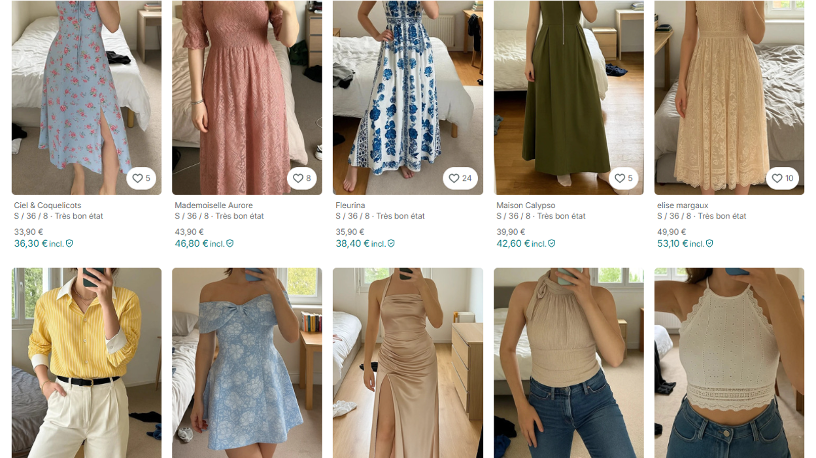
Si on élargit à d’autres sujets qui peuvent parler à tout le monde, il y a d’ailleurs eu cette enquête sur la présence de contenus générés par IA sur des plateformes comme Vinted [N.d.A. : d’abord révélé par l’influenceur écolo Johan Reboul], même si on est moins sur de la fraude que de la tromperie. La question de la traçabilité, elle est aussi importante à ce niveau-là.
De toute manière, si on regarde les choses à échéance plus longue, il n'y aura pas de vision binaire des choses. Du synthétique, il y en a déjà partout en ligne, alors imaginez dans 10 ans. L'idée ça va donc être de taguer ces contenus synthétiques pour savoir à quel niveau, à quel degré, le contenu que vous avez en face de vous a été généré.
Philosophiquement, ça posera d'ailleurs des questions assez passionnantes : à partir de quel "pourcentage" de contenu généré par une IA on considèrera qu'un document est généré par un humain, ou bien seulement par une IA ?
Il y a un autre exemple qui m’intéresse, celui de la musique. Spotify, on le sait, va à fond sur l'IA. À l’inverse, les français de Deezer essaye de tracker tout ça, et en parle ouvertement. Ce qu'ils utilisent comme outil, c'est quelque chose qui se rapproche de ce que vous faites ?
NBG : C'est une excellente question. Je les ai croisés, Deezer, il y a quelques semaines lors d’un événement. On devait se parler, on s'est loupé, on doit se revoir à la rentrée. En gros, ce qu'ils proposent, c'est proche de ce qu’on fait, même si je m'interroge encore sur certains points.
Quoi qu'il en soit la démarche est louable, et leurs annonces en ce sens sont vraiment pertinentes. Si des gens ont envie d'écouter de la musique générée par IA, grand bien leur fasse, mais l'important c'est de bien savoir quand tu écoutes cette musique qu'elle est générée par une IA. Là est le coeur du problème, encore une fois.
Jusqu’ici, on a plutôt parlé des entreprises qui hébergent du contenu pouvant être généré par IA. Mais parlons de l’éléphant dans la pièce : les boîtes qui elles permettent la génération desdits contenus, comme OpenAI avec ChatGPT.
Celles-ci, on l’a dit, vont bientôt être obligées de taguer ces contenus pour qu’ils soient identifiés comme générés IA. Comment allez-vous faire pour proposer une offre pertinente si aucun des acteurs n’utilisent la même méthode de tag ?
NBG : Et bien ce n’est pas évident de répondre à ta question, car rien n’est décidé. Nous rencontrons la Commission Européenne à ce sujet à la rentrée, et la grande question qui doit être tranchée c’est : quelle méthode, parmi celles que l’on a déjà évoqué tout à l’heure, va permettre de le faire ?
La question que tu poses, c’est celle de l'interopérabilité, et cela va demander des compromis. La métadonnée, on l’a dit, ce n'est pas robuste, mais c'est plus facile de faire de l'interopérabilité parce que tu as juste à lire la métadonnée de chaque fichier, c’est facilement accessible. Pour le cas du watermark, il faudra mettre en place un "meta détecteur" qui permettra de détecter tous les différents type de marques.
Du côté du "finger printing", on l'a vu, il faudrait une gigantesque base de données de tout ce qui est produit par des IA génératives, ce qui me semble franchement inenvisageable, aussi bien techniquement que du point de vue de la consommation. Pour ce qui est de la blockchain enfin, idem : ce serait une catastrophe d'un point de vue écologique, et ça parait de toute façon trop compliqué pour l'adapter aux volumes de production des IA génératives, aujourd'hui et encore plus demain.
Il faut être clair : l'Europe joue gros, elle ne peut pas préconiser un système trop faible, comme choisir une traçabilité unique via les métadonnées, car ce serait en contradiction directe avec le texte même de l'AI Act, qui exige que la méthode soit robuste et efficace. Ce serait inefficient en pratique et ne participerait pas du tout à la lutte contre la désinformation, qui est bien la volonté politique première dernière le fameux article 50 de l'AI Act.

Il y a un sujet dont nous n’avons pas encore parlé, et qui nous tient pourtant tous les deux à cœur : la souveraineté numérique. En quoi Label4AI s’inscrit dans cette dynamique, et pourquoi c'est important ?
NBG : Je dirais qu’il y a trois aspects. Au niveau des capitaux, déjà : on est financé uniquement par des fonds européens. Toutes les boites qu'on approche, tous les financeurs potentiels avec qui on discute sont européens.
Deuxièmement, les infrastructures sur lesquelles on se repose sont des infrastructures 100% européennes. C'est du OVH aujourd’hui.
Troisièmement, même au niveau des outils qu'on utilise en interne, on évite les américains. Repository, mail ou même outils collaboratifs… on utilise Proton, on utilise Mattermost [N.d.A. : équivalent de Slack certes créé aux USA mais dans un format libre auto-hébergeable]. C’est une vraie conviction, d’éviter cette dépendance aux outils propriétaires américains.
Mais j’irai plus loin : le fait qu'on soit européens est vraiment revendiqué du point de vue de notre ADN, de nos valeur, de notre compréhension de la réglementation, des enjeux éthiques… ce qui fait qu’on doit pouvoir toucher un marché que les acteurs américains ne pourront pas aller chercher. On est dans un domaine où l’on doit être de vrais tiers de confiance. Compte tenu de l'actualité des GAFAM, qui accepterait de confier les clés du camion de l'authentification et de la détection des contenus générés par IA et de la détection des contenus à des boîtes comme Microsoft ou Meta ?
Il en va, au fond, de l'indépendance stratégique de l'Europe : doit-elle être dépendante d'acteurs extra-européens pour pouvoir distinguer le vrai du faux? Ce serait se mettre entre les mains d'acteurs politiques qui, on le voit bien avec l'actualité récente, pourraient en jouer pour manipuler l'Europe et donc ses citoyens. Cela nous semble inenvisageable, et ce serait d'autant plus dommage que nous avons la capacité scientifique de produire des alternatives européennes.
On a bien des concurrents américains [Get Real et Reality Defender, principalement]. Mais on n’est pas là pour dire, comme souvent dans le numérique malheureusement aujourd’hui : "c'est moins bien, mais c'est souverain". Non : technologiquement, c’est aussi solide, voire encore davantage... et en plus c'est souverain ! On propose un vrai système de valeur, qui est lié à nos rapprochements avec la recherche, à notre rigueur scientifique.
L’IA générative est beaucoup utilisée pour la fraude, et c’est aussi parce que c’est un outil très facilement accessible, à très bas coût… tu penses que cet état de fait va être conservé ?
NBG : Je ne sais pas pourquoi les gens sont surpris, ou plutôt j'espère qu'ils ne le seront pas. C'est comme d'habitude avec les outils de ce type : on ouvre d’abord les vannes à fond, et puis après, il y aura de la pub, et puis les prix vont augmenter, etc. Les dernières fonctionnalités de ChatGPT commencent déjà à être payantes, et des publicités commencent à apparaître. Les valorisations boursières qui ont été atteintes, ce n'est pas avec des abonnements à 20€ par mois, même à l’échelle du monde, que ça va être rentabilisé, il ne faut pas être dupe.
Tu parles des valorisations des acteurs de l’IA. On pense aux chiffres délirants qui entourent OpenAI, notamment. La bulle de l’IA, tu y crois ?
NBG : Oui, c'est certain, elle va craquer, cette bulle. Plein de boites vont s’effondrer parce que leur business ne repose sur rien. Que l’IA soit une techno ultra prometteuse, moi je n’ai aucun doute là-dessus. D'un point de vue puissance et d'un point de vue capacité, c'est formidable. Par contre, on a mis la charrue avant les bœufs en disant que ça permet de tout faire. La promesse que ce soit massivement adopté pour des choses réellement utiles et qui rapportent massivement, à ce stade c’est moins évident.
D'ailleurs, on voit là aussi pas mal de cas de fraudes, de fausses boîtes basées sur rien, comme Builder.ai.
Pour conclure, j’aimerais que l’on parle de ta vision de l’IA de manière générale, notamment sur l’IA générative et les LLM (Large Language Model).
NBG : Personnellement, je pense qu’il n'y aura pas de marche arrière, parce que même si les LLM n'existeront peut-être plus en "standalone" [N.d.A : utilisé en tant qu'outil indépendant, comme dans le cas de ChatGPT aujourd’hui] ils seront intégrés dans l'agentique ou dans la plupart des outils bureautiques. Et c'est la stratégie : Microsoft, par exemple, utilise l’IA pour faire levier sur ses produits traditionnels et créer une dépendance supplémentaire.
Le problème avec ces outils, c’est que les gens les utilisent pour tout et n'importe quoi parce que des entreprises les poussent partout, alors qu’ils sont très performants pour des tâches bien spécifiques et identifiées.
C’est ce qui fait qu’à ce stade cela créé autant de problèmes que ça n'apporte de solutions. Voire plus de problèmes que de solutions… Là, c’est comme au début du Web3, avec beaucoup d’énergumènes qui se servent de l'IA pour se faire du business facilement. Je veux dire, mon feed LinkedIn est devenu terriblement chiant. C’est 80% de ChatGPT avec le même ton, les mêmes formations bidons…
Il n’empêche qu’avec cette technologie, on a passé un cap dans la façon de travailler et dans la façon d'utiliser l'informatique de manière générale. C'est le changement technologique le plus radical que j'ai eu l'occasion de voir de ma vie. En termes d'utilisation et de vitesse d'intégration de ces outils, je n’ai jamais vu ça ; même le smartphone, ça a été plus lent.
C’est parce que je crois qu’il n’y a pas de retour en arrière possible que je préfère poser cette question : comment peut-on prendre nos précautions ?
Un grand merci à Nicolas pour ses réponses et cet échange passionnant. J'ai appris beaucoup sur les méthodes qui peuvent permettre de "tracker" et traquer les contenus générés par l'IA, et dieu sait que je pense que cela sera capital pour la suite.
Si je suis moins enthousiaste que Nicolas sur les capacités des LLM, il est indéniable que ces outils ont déjà un impact majeur sur nos vies, un impact qui va s'accentuer.
Et cela même si la bulle "pète", même si leur développement ralentit. Il faut donc se prévenir contre les dérives d'entreprises comme OpenAI, grâce à la régulation européenne, et grâce à des projets comme Label4AI.
J'ai en tout cas hâte de connaître la suite des avancées sur ce sujet, et ce que vous avez pensé de cette interview !
Après ce grand entretien, on enchaîne avec quelques news tech qui m'ont marqué cet été.

L'été a été riche en plus ou moins bonnes nouvelles sur le front de la tech, et loin de moi l'idée de vous faire le résumé complet des événements. Mais j'ai tout de même été marqué par quelques annonces et actualités clés, dont voici un résumé succinct :
- EVIL META : Pas de vacances pour les dingueries autour de l'IA générative. Ces dernières semaines, on aura vu Open AI étaler une nouvelle fois son absence totale d'éthique et de contrôle sur son outil majeur (maintenant dans une V5 🤷♂️), avec la terrible histoire du suicide assisté par ChatGPT d'un jeune américain. Article difficile ⚠
Mais il faut aussi parler de ce qui s'est passé du côté de Meta : pour l'entreprise maléfique par excellence, il n'y a pas de problème à ce que ses IA génératives (poussée partout sur Whatsapp, Instagram ou Facebook, pour rappel) "engagent une conversation romantique ou sensuelle avec un enfant".
C'est ce qu'a révélé un excellent article de Reuters, dont la lecture n'est pas toujours facile, et que j'ai analysé et résumé en français dans ce post.
Une news qui a précipité ma décision de quitter les applis Meta d'ici 2026, sur le plan personnel au moins. Si vous connaissez des alternatives que vous aimez, n'hésitez pas à me les partager en commentaire.

- ALTERNATIVES : À propos d'alternatives à la tech US : l'idée de construire un guide complet pour s'extirper des monopoles tech états-uniens me trotte dans la tête depuis longtemps. Depuis plus d'un an, et encore davantage depuis la réélection de Trump et l'allégeance des Big Tech.
Mais quand d'autres le font extrêmement bien, il faut savoir rendre à César ! Alors je vous partage le super guide construit par Paris Marx dans le cadre de son excellente newsletter en provenance du Canada (en anglais) 🇨🇦
J'y ai ajouté quelques outils français et européens de qualité, ainsi que ma propre suite de services souverains du quotidien, dans ce post.

- EVIL MICROSOFT ? Nous en avions parler dans le numéro 16 de TFTT : les liens de Microsoft avec une armée génocidaire ont continué à faire parler, et ont fait réagir comme jamais auparavant. C'est encore une fois The Guardian qui a révélé l'affaire, dont le timing coincide avec une manifestation jamais vue auparavant : des employés ont lancé un sit-in au sein du siège social de Microsoft à Redmond... ce qui a conduit a des arrestations par la police.
La pression interne comme externe ne faiblit en tout cas pas. Je vous en parle dans ce post.
Vous me direz, tout ça est assez cohérent quand on sait que le plan de l'administration Trump pour Gaza est de "relocaliser volontairement" les Palestiniens, d'établir un contrôle US de la zone, et la transformer en "étincelant resort de tourisme et en pôle dédié aux technologies de pointe", d'après cet article du Washington Post.
Même dans un film un tel plan paraitrait fou. Mais voici la réalité dans laquelle nous vivons, donc.

- IMPACT : un dernier sujet en guise de conclusion, pour évoquer un dernier des cavaliers de l'apocalypse, Google. L'entreprise a lâché des infos sur l’impact environnemental de son IA générative Gemini, mais ce ne sont évidemment pas les plus pertinentes...
Surtout : "laisser Google définir le narratif sur les coûts environnementaux de l'"IA", c'est comme laisser les fabricants de tabac définir le narratif sur les effets du tabagisme passif".
Voici un excellent article de Next.ink sur le sujet, et quelque chose me dit qu'on va reparler du sujet dans notre prochain numéro...

Voilà, c'est tout pour cette rentrée, et c'est déjà pas mal !
On se retrouve bientôt en septembre pour un 19ème numéro de Tales From The Tech.
D'ici là, n'hésitez pas à partager le format autour de vous, cela me ferait très plaisir. Et à me faire part de vos retours.
Vous pouvez le faire en commentant l'article sur tftt.ghost.io, ou directement via mes différents réseaux.
Vous souhaitez soutenir TFTT ? Consultez vos abonnements sur la plateforme ou faites un don ponctuel 🙏
Merci à toutes et tous,
Thomas ✊
PS : Tales from the Tech est garanti sans IA générative, pas sans fautes